In today’s classrooms, voice-enabled technologies promise to revolutionize learning – from reading assistants to interactive language tools. Yet these systems face a fundamental challenge: they often fail to understand their primary users – the children themselves.
While speech recognition has made remarkable strides in recent years, the gap between performance on adult and child speech remains surprisingly wide. The current state-of-the-art speech recognition model is Whisper. In 2022, Whisper was shown to reduce transcription error rates by an average of 55 percent when compared to previous best-in-class solutions. This is because Whisper does an excellent job transcribing adult voices in a variety of contexts.
Under ideal circumstances, where an adult is reading prepared speech without background noise, Whisper achieves an average word error rate (WER) as low as 3 percent. But the same model scores a not-so-great 25 percent WER when transcribing child voices in similar conditions, or a gap of 22 percentage points.
This performance gap might seem insurmountable given the complexity of child speech. But emerging research reveals a path forward: smaller, more diverse datasets combined with strategic fine-tuning can achieve dramatic improvements, reducing error rates for child speech by at least 20 percent and by as much as 96 percent – about 50 percent for most of the datasets that were tested. This shrinks our estimate for the gap between adult and child accuracy down to 11 percentage points. This is a signal that speech recognition technology can work for young learners, but only when child voices are represented in the training data.
The Child Voice Challenge
Children’s speech patterns differ fundamentally from adults’ in ways that confound even the most advanced AI systems. It’s not simply about higher-pitched voices – children are actively developing their speaking abilities, with different sounds mastered at different developmental stages. Children’s vocal tracts are physically smaller and continue growing until adolescence, creating unique acoustic properties that change as they develop.
Their speech exhibits greater variability in timing, with irregular pauses, false starts, and incomplete utterances that are natural parts of language acquisition. Young speakers often struggle with complex consonant clusters, substitute easier sounds for difficult ones, and may not have fully developed the motor control necessary for consistent articulation.
Children's speech patterns differ fundamentally from adults' in ways that confound even the most advanced AI systems. It's not simply about higher-pitched voices – children are actively developing their speaking abilities, with different sounds mastered at different developmental stages.
Additionally, children’s speech rates vary significantly – they may speak rapidly when excited or slowly when concentrating, creating temporal patterns that differ markedly from the more predictable rhythms of adult speech. This natural variation creates significant challenges for automated systems primarily designed for adult speech.
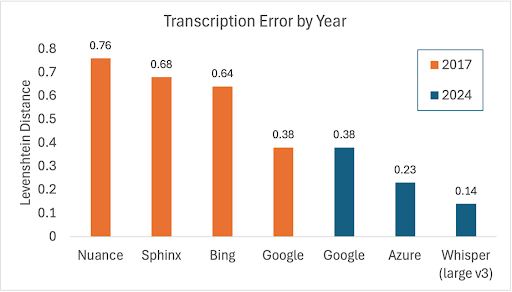
Recent research illustrates the scale of this challenge. In 2017, Kennedy and colleagues tested various ASR models on child voices and found dismal performance. By 2024, Jansenns and colleagues revisited this question using the same dataset and discovered significant progress, with OpenAI’s Whisper v3 emerging as the top performer. Yet despite these improvements, the performance of these systems with child voices still lags behind their performance on adult voices.
Beyond Volume: Quality, Representation Matter
The persistent performance gap reveals an important insight about AI development: sheer volume of data isn’t enough. Even with Whisper’s massive training dataset (680,000 hours), the base model struggled with child speech without specific fine-tuning. This challenges the common assumption that larger datasets automatically lead to more inclusive AI systems.
One study found that non-native children’s speech posed particular challenges, with error rates varying dramatically across different linguistic backgrounds:
| Dataset | Speakers | English | Baseline WER | Fine-tuned WER |
|---|---|---|---|---|
| My Science Tutor | American Children | Native | 25% | 12% |
| PFSTAR | British Children | Native | 74% | 3% |
| PFSTAR | Swedish Children | Non-native | 30% | 7% |
| PFSTAR | German children | Non-native | 78% | 31% |
| PFSTAR | Italian Children | Non-native | 35% | 4% |
| CMU Kids | American Children (read-aloud) | Native | 7% | 2% |
| Speech Ocean | Chinese Children | Non-native | 29% | 14% |
| Libri TTS | Adults | Native | 5% | 4% |
Table 1. Performance of baseline Whisper v2 (large) and finetuned version on different datasets as reported in Jain et al. (2023). Measured in WER (Word Error Rate, lower is better).
These variations highlight that the linguistic background of the speaker, as well as the speaker’s age, has a dramatic impact on speech recognition performance. The baseline WER for German children speaking English was nearly 80 percent, but American children reading a book out loud had a baseline error rate of only 7 percent.
The good news is that fine-tuning Whisper v2 improved its performance for all datasets reported in the study. Importantly, the researchers achieved their best results by carefully combining diverse datasets that included both native and non-native child speech. This approach dramatically reduced error rates – improving performance for British children from 74 percent to just 3 percent after fine-tuning, a reduction in WER of 96 percent.
Perhaps most encouraging, even small amounts of carefully curated data from underrepresented groups (as little as 10 percent of target data) can significantly improve performance for those populations. This suggests that meaningful progress doesn’t necessarily require massive data collection efforts but rather thoughtful curation focused on inclusion.
Perhaps most encouraging, even small amounts of carefully curated data from underrepresented groups (as little as 10 percent of target data) can significantly improve performance for those populations. This suggests that meaningful progress doesn't necessarily require massive data collection efforts but rather thoughtful curation focused on inclusion.
Pathways to Better Systems
How can developers create more inclusive ASR systems for children? The research points to several promising approaches:
- Fine-tuning foundation models: Fine-tuning a foundation model such as Whisper on a relatively small dataset of diverse child voices appears to be a viable strategy. This builds on existing capabilities while addressing the specific challenge of child voices.
- Prioritizing diversity: Success requires intentionally including various accents, ages, and linguistic backgrounds rather than simply collecting more data.
- Incremental improvements: Recent advances in Whisper models have come through both improved training strategies (v2) and supplemental data (v3), suggesting multiple pathways to continued improvement in foundation models.
The ASR Data Collection Dilemma
These technological needs bring us back to a fundamental tension: improving ASR for children requires more representative data, but collecting such data raises significant privacy and ethical concerns.
The challenges are substantial. Could researchers use public data, perhaps from social media platforms like YouTube? While economical, this approach raises critical questions:
- Would such datasets be sufficiently diverse, and how would that diversity be assessed?
- Is it ethical to use this data? Can children provide meaningful consent for AI training?
- Would this data represent the educational contexts where ASR is most needed?
Implications for AI Fairness and Inclusion
The challenges facing child speech recognition mirror broader questions about fairness and representation in AI systems. When voice technologies perform poorly for certain demographic groups, they risk perpetuating educational inequalities rather than addressing them. Children who might benefit most from assistive speech technologies – including those with speech differences, non-native speakers, or students from underserved communities – are often the least likely to be represented in training datasets.
This creates a concerning feedback loop: as voice technologies become more prevalent in educational settings, children whose speech patterns align with training data receive better technological support, while others face repeated failures that may discourage engagement with learning tools. Addressing this disparity requires not just technical solutions but a fundamental commitment to inclusive design principles from the earliest stages of system development.
Teachers and speech therapists could use these tools to track progress more effectively, provide personalized support, and identify when additional intervention might help. Intelligent tutoring systems could provide real-time pronunciation feedback for language learners, while assessment tools could offer objective measures of reading fluency and comprehension.
Bridging the Gap
Speech recognition technology has enormous potential in educational settings – from helping identify early signs of speech disorders to supporting language development and literacy. Teachers and speech therapists could use these tools to track progress more effectively, provide personalized support, and identify when additional intervention might help. Intelligent tutoring systems could provide real-time pronunciation feedback for language learners, while assessment tools could offer objective measures of reading fluency and comprehension. For children with special needs, speech recognition could enable new forms of assistive technology that adapt to individual communication patterns and support independence in learning environments.
Realizing this potential requires addressing both technical challenges and ethical considerations. The path forward demands intentional efforts to include diverse voices in AI development while respecting privacy and consent. Without such efforts, voice technologies risk leaving behind the very users who might benefit most from them.
Recent research provides hope that this gap can be closed. With targeted fine-tuning and diverse datasets, error rates for child speech have dropped dramatically. The question now is whether developers will prioritize inclusion and representation as these technologies continue to evolve.
For educators, parents, and technology developers alike, the message is clear: creating truly inclusive voice technologies requires intentional design, diverse representation, and careful consideration of privacy and ethics.
