What if learning a language isn’t so different from how ChatGPT and other AI language models are trained? My recent research suggests there are surprising parallels between how second language learners and large language models process language—and this connection might transform how we assess language skills in educational settings.
The Prediction Game
Think about how you read or listen to someone speak. Your brain is constantly guessing what word comes next. When someone says “Please pass the…” your mind has already jumped ahead to “salt,” “butter,” or “remote.” This predictive process happens automatically, mostly beneath conscious awareness.
Language models like BERT (the technology behind many AI writing tools) do something remarkably similar. They’re trained to predict missing words based on surrounding context. Feed BERT the sentence “The cat sat on the ___” and it will assign high probabilities to words like “mat,” “couch,” or “floor” and very low probabilities to words like “ceiling” or “algorithm.”
Here’s the intriguing part: more proficient second language learners tend to make word choices that are more predictable–not in a boring way, but in a conventional, natural-sounding way. They’ve learned the patterns of which words typically go together.
Measuring the Predictable
In my research, I developed a metric called PredictabilityBERT that uses artificial intelligence to measure how conventional and expected the word choices are in a piece of student writing. The process works like this:
- Take a student’s essay
- Mask out one word at a time (like a fill-in-the-blank exercise)
- Use BERT to predict what word should fill each blank based on the surrounding context
- Calculate how well the student’s actual word choices match what the language model expected
A student who writes “I strongly believe” gets a high predictability score because that’s a conventional phrase. A student who writes “I powerful believe” gets a lower score—not just because it’s grammatically incorrect, but because the language model (BERT) has a hard time predicting that sequence of words.
To illustrate what this looks like in practice, I visualized the predictability score of each word in a sample of writing with a text heatmap. More predictable words are highlighted in green, while less predictable words are not highlighted.

What We Found
My colleagues and I tested this approach on two major datasets:
The Lexical Proficiency Corpus: 480 writing and speaking samples from English language learners at different proficiency levels, all rated by expert human judges.
The TOEFL 11 Corpus: 11,000 essays from test-takers with 11 different first language backgrounds, all scored using the official TOEFL rubric. TOEFL, or the Test of English as a Foreign Language, is one of the most trusted English language proficiency tests.
The results were striking.
Strong Correlations with Expert Judgments
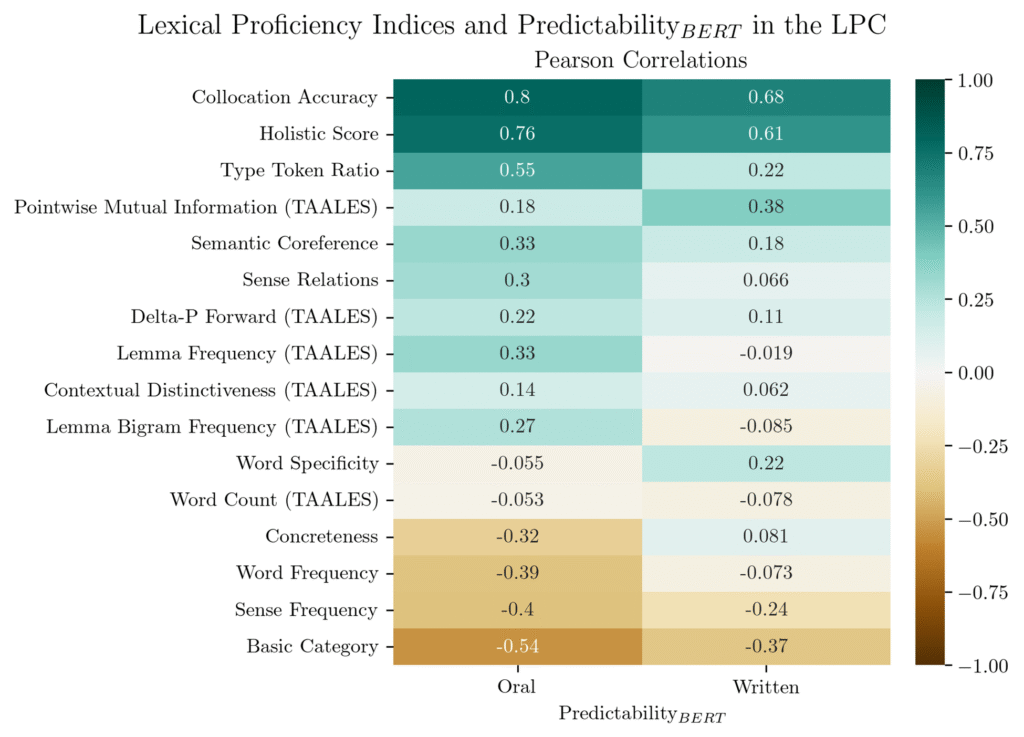
PredictabilityBERT correlated with human expert ratings of collocation accuracy (r = 0.80 for spoken data, r = 0.67 for written). In other words, when human raters said a student was using word combinations accurately and naturally, the AI measure agreed.
The measure also correlated strongly with overall lexical proficiency ratings (r = 0.60-0.73), suggesting it captures something fundamental about language skill.
Included below is a correlation table showing how PredictabilityBERT correlates with human ratings of writing characteristics, as well as automatic metrics calculated using a tool called TAALES (Tool for the Automatic Analysis of Lexical Sophistication).
Strongest Predictor of Proficiency
When we built a statistical model to predict TOEFL writing scores using multiple linguistic features, PredictabilityBERT emerged as the strongest predictor by far, stronger than traditional measures like:
- Word frequency (how common the vocabulary is)
- Bigram frequency (how often word pairs appear together)
- Association strength measures (how strongly words are linked)
- Contextual distinctiveness (how much information words convey)
The full model explained 59 percent of the variance in proficiency levels, which is remarkably high for automatic linguistic analysis. For context, previous studies using traditional lexical measures typically explained 24-42 percent of variance.
| Predictor | Standardized Coefficient |
|---|---|
| (Intercept) | 2.574** |
| PredictabilityBERT | 1.142** |
| Lemma Frequency | 0.153** |
| Lemma Bigram Frequency | -0.098** |
| Pointwise Mutual Information | -0.046+ |
| Delta-P Forward | 0.100** |
| Contextual Distinctiveness | 0.505** |
| N=11,000 | |
| Pseudo-R2 Marginal | 0.585 |
| Note: +p < 0.1, **p < 0.01 | |
Why Does This Matter for Education?
This research has several practical implications for educators and assessment developers:
1. Rethinking What "Good Vocabulary" Means
We often think about vocabulary development in terms of knowing more words or using less common words. But proficiency also involves knowing which words naturally go together. A student might know the words “make” and “homework” separately, but a more proficient learner knows that we typically say “do homework,” not “make homework.”
PredictabilityBERT captures this dimension of language knowledge, the conventionality and naturalness of language use that goes beyond individual word knowledge.
2. Automated Feedback Possibilities
Because this measure can be calculated automatically, it opens the door for real-time feedback tools. Imagine a writing tool that could highlight unconventional word combinations for students, not to discourage creativity, but to help them understand which phrases sound natural to native speakers.
Current grammar checkers flag obvious errors, but they don’t typically identify phrases that are technically correct but sound unnatural, like “powerfully believe” versus “strongly believe.”
3. Understanding Both Oral and Written Language
Interestingly, predictability scores were actually more strongly correlated with proficiency in spoken language than written language. This makes sense: when we speak, we rely more heavily on automatized, formulaic language patterns because we don’t have time to plan and revise.
This suggests that measuring predictability might be particularly valuable for assessing oral proficiency, where conventional language patterns serve as cognitive shortcuts.
4. More Holistic Assessment
Traditional vocabulary assessments often focus on breadth (how many words you know) or on individual word knowledge. PredictabilityBERT captures something different and complementary: how well students have internalized the probabilistic patterns of word use.
Think of it as the difference between knowing the rules of chess and developing a feel for which moves are strong. Proficient language users have developed that “feel” for which words naturally combine.
The Theory Behind Word Patterns
Why do more proficient learners make more predictable word choices? The answer lies in how we acquire language.
According to usage-based theories of language learning, we learn language primarily through exposure to many examples. Every time we encounter a phrase like “strong coffee” or “make a decision,” our brains register those patterns. Over time, these patterns become internalized, and we start to implicitly know which words tend to appear together, even without consciously memorizing rules.
In this view, language learners are essentially developing their own internal prediction engines, constantly learning to anticipate what comes next based on patterns they’ve absorbed. More proficient learners have fine-tuned their prediction engines through more exposure and practice.
The AI Connection
Here’s where it gets really interesting: language models like BERT are essentially doing the same thing, just at massive scale and with explicit mathematical probability. BERT was trained on billions of words, learning which words tend to appear in which contexts. It has no understanding of meaning in the human sense—it’s just a very sophisticated pattern recognition system.
Yet this pattern recognition system, when applied to student writing, correlates remarkably well with human expert judgments. This suggests that a significant component of what we call “language proficiency” might be exactly this pattern recognition ability: knowing which words naturally go together.
This doesn’t mean language is only pattern recognition. Creativity, meaning-making, and authentic communication are crucial. But the ability to use conventional patterns provides the foundation that allows for more complex and creative language use.
Limitations and Future Directions
No measure is perfect, and PredictabilityBERT has some important limitations to consider:
Non-linearity across proficiency levels: This research focused on intermediate to advanced learners. With beginners, we might see high predictability for a different reason: beginning language learners often rely heavily on a small set of memorized phrases. With very advanced learners, we might see more creative and surprising (but effective) word choices. Therefore, we suspect that the relationship between predictability and proficiency might not be linear across all levels.
Black box problem: While we can measure predictability, BERT doesn’t tell us why a particular word is predictable in a given context. We can’t easily identify which specific contextual cues the model is using to make its predictions. This limits the actionable feedback we can provide to students. On the other hand, explainable AI (xAI) techniques are emerging that could help us to understand how contextual cues influence predictability. When paired with predictability measures, these techniques could allow for rich, real-time feedback.
Corpus dependency: PredictabilityBERT reflects the patterns in the texts BERT was trained on (Wikipedia and books). Different language models trained on different corpora would yield different predictability scores. But this limitation is not specific to language models. Any measure of “conventional” language use depends on what community’s conventions we’re referencing.
The Bottom Line for Educators
Whether you’re teaching English language learners, developing assessments, or exploring educational technology, this research offers a new lens for thinking about language development:
Language learning involves developing internal prediction engines. More proficient learners have better-tuned engines that predict conventional word patterns. This isn’t about memorizing rules or lists of collocations; it’s about absorbing patterns through meaningful language exposure.
We can now measure this dimension automatically. While we’ve long recognized the importance of conventional, natural-sounding language use, we haven’t had good tools to measure it automatically. PredictabilityBERT offers one such tool.
Assessment should consider multiple dimensions. A comprehensive understanding of language proficiency needs to include not just vocabulary breadth, syntactic complexity, or grammatical accuracy, but also this dimension of conventionality and naturalness in word combinations.
AI and human learning might not be so different. The parallels between how language models and language learners process language aren’t just interesting—they’re potentially profound. Both are, in a sense, prediction engines being tuned through exposure to patterns. Understanding these parallels might help us better support human language learning.
The full research paper, “Word Predictability as a Measure of Second Language Proficiency” (under review), provides detailed methodology and complete results. Code and materials are available on GitHub for researchers interested in applying this approach to their own datasets.

1 thought on “The Hidden Link Between Language Learners and Language Models”
Um… You’re basically describing the information theoretic measure “perplexity” which has been widely used for 40 or 50 years.