Introduction
In the world of machine learning, artificial intelligence (AI), and research, the quality of a dataset is only as strong as the process used to create it. High-quality annotation requires more than just labeling data. It demands a structured framework to ensure validity and reliability.
There are multiple approaches to annotation, such as thorough training and norming to establish a gold standard, crowd-sourcing to enable scaling, or relying on un-normed experts for domain-focused annotation. Project leads should select an approach based on the annotation project’s goals and use cases, while considering the trade-offs between scale, cost, time, and precision.
This article focuses on rigorous, thorough training and norming, outlining a three-phase approach designed to maximize alignment and encourage high Inter-Rater Reliability (IRR), ensuring that the resulting data is of a gold standard quality.
When to Use A “Thorough Training and Norming” Approach
A thorough training and norming approach is a highly rigorous method that can result in gold standard annotations. It is a common approach when high-quality annotations are required, such as when creating evaluation benchmarks or specialized datasets. This approach is also beneficial for complex tasks where nuance is critical. For example, annotating student responses to math questions for potential misconceptions.
While annotation quality is high and consistent with this approach, the thoroughness of the process can make it time-consuming and costly, especially if there is interest in annotating a large amount of data. As a result, the ability to increase scale quickly is low.
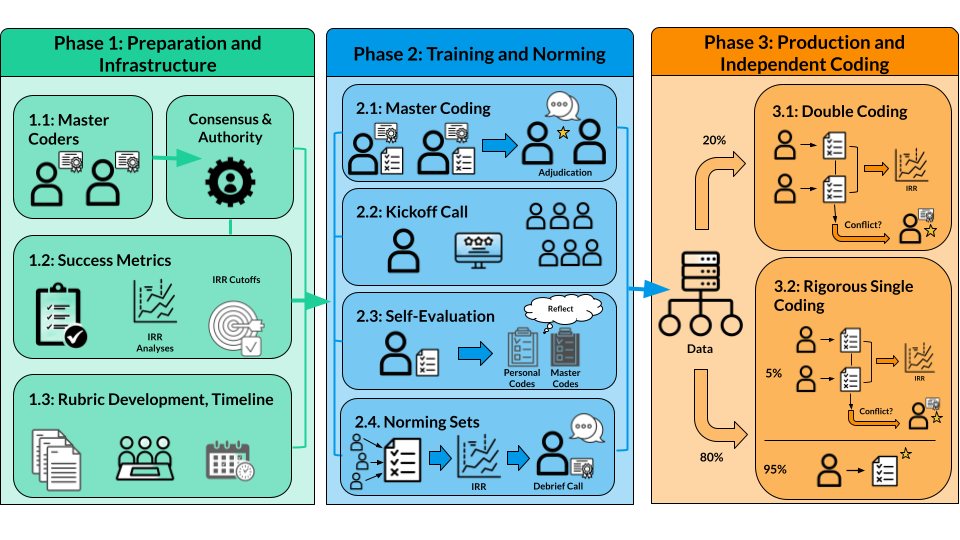
Phase 1: Project Preparation and Infrastructure
Before any data is labeled, the team must establish the groundwork to ensure success and methodological rigor. Multiple aspects of the annotation process should be determined before annotation begins.
Master Coders
Master coders are experts with ample experience in the subject matter of the annotation task. For example, if annotating for misconceptions in students’ open response math answers, master coders should have the knowledge to identify gaps in student math explanations, such as math teachers or tutors with experience in interpreting student work.
Before annotation, recruit and select two master coders who will work together. Their consensus creates the gold standard, and they serve as the final authority on rubric interpretation and annotation labels throughout the project, guiding and training other annotators on labeling.
Success Metrics
To ensure reliability and gold standard quality, success metrics must also be defined before annotation. The IRR analyses and cutoff values should be decided on in advance to ensure high methodological quality.
IRR analyses may include Cohen’s Kappa, Percent Perfect Agreement, or others. Ideally, more than one analysis should be performed, and/or accompanied by other evaluation methods for high confidence in agreement. These analyses should be chosen based on the annotation task and be used to assess annotator agreement. Annotators should reach the chosen cutoff, as determined by research related to the particular analysis, by the end of the training and norming.
To ensure reliability and gold standard quality, success metrics must also be defined before annotation. The IRR analyses and cutoff values should be decided on in advance to ensure high methodological quality.
Tools and Environment
Particularly when annotating a large amount of data, or when many annotators are contributing to a project, selecting the right annotation platform is critical. The tool should enable efficient data processing and facilitate quality control features, including minimizing the chance for human error.
The annotator experience should also be considered, as a user-friendly tool will result in quicker and more confident annotations. Ease of use on the backend is equally important. A tool that is easy to set up according to your annotation needs and easy to extract all the required details collected from annotators will ease the process and reduce the time required to obtain and organize the annotations.
The article Choosing the Right Annotation Platform outlines more on this decision point.
Rubric Development
A crucial piece of annotation is the rubric development. All master coders and annotators will work based on the rubric. All users of the rubric must be able to understand and differentiate the various labels and their descriptions for reliability to be achieved. Clarity is key.
The rubric should undergo multiple revisions with feedback from an advisory board that includes experts in the field who may be impacted by the annotations. For example, if annotating math misconceptions in student work for AI and machine learning algorithms, the advisory board should include experts in math cognition, AI, Natural Language Processing, linguistics, etc. Multiple perspectives are optimal to support clarity and understanding by as many individuals as possible.
Once a consensus is achieved, test the rubric on a sample of data. This hands-on use of the rubric can identify aspects where implementing the rubric causes confusion or uncertainty. Obtaining codes from multiple individuals for each data point in the sample, along with their explanation for why they selected the code, will help show where discrepancies may appear between annotators. These discrepancies may be able to be mitigated by further editing the rubric or ensuring discussions on the rubric address discrepancies found in the testing.
Timeline and Capacity Planning
As with any project, required timelines and other capacity needs must be assessed and planned for accordingly.
Timelines should consider and set anticipated deadlines for steps such as data collection and preparation, rubric development and iteration, tool and environment setup, annotator and master coder hiring, annotation, and annotation data collection and organization.
For annotation, capacity needs may vary depending on aspects such as the amount of data being handled and annotated, the number of annotators being managed, and the number and capacity of employees.
When determining how much data to annotate, consider the amount of data required to make beneficial use of the annotations. For example, if the annotation rubric contains four math misconception labels, enough data should be annotated such that there is data associated with each misconception label in the rubric. More data should be annotated than is required for final use or shared access. After annotation, annotated data may be discarded, particularly if they would contribute to algorithmic bias.
Once the amount of data required to be annotated is determined, this information, in conjunction with the required timeline, can be used to determine the minimal number of annotators required for the project. More annotators should be hired than the minimum required for the project, as annotators may have unexpected life events that interfere with progress, or annotators may not meet the required reliability metric after training and norming.
Employees will be needed for data preparation and handling, tool setup, and advisory board and annotator communications and management. A greater number of experts, advisors, and annotators will require more time and effort.
It is suggested to annotate a sample of the data with the finalized rubric to: 1. Obtain an estimate of how much time it will take an annotator to assign the annotation codes to a data point, and 2. Assess the potential rate of each annotation label occurring in the data for sample size estimation.
As with any project, required timelines and other capacity needs must be assessed and planned for accordingly. Timelines should consider and set anticipated deadlines for steps such as data collection and preparation, rubric development and iteration, tool and environment setup, annotator and master coder hiring, annotation, and annotation data collection and organization.
Phase 2: Training and Norming
The goal of this phase is to transition the annotators from a conceptual understanding of the annotation task to a practical, aligned application of the rubric labels. Enough data should be selected for this phase such that each set supports the annotator’s understanding and results in valid analyses. There are four primary stages to obtain gold standard codes and align annotators:
Master Codes
Gold standard codes must be obtained for the training and norming to align annotators and run reliability analyses. This begins with master coders attending an introductory call to discuss the rubric with the rubric developers and receive an overview of the annotation platform. After thoroughly discussing the rubric, all master coders blind code, providing annotations for every data point in the training and norming sets independently. This results in multiple annotations per data point, which are then adjudicated to determine the final, gold standard code for each. Any instances in which the master coders selected different codes are reviewed by the master coders to further discuss and agree on a final code.
This phase is made up of two primary sections of data: self-evaluation and norming. The master code process should be performed for all data points in these set types.
The Kickoff Call
All annotators join the kickoff call, in which they receive guidance on the annotation platform, work and timeline expectations, and a comprehensive walkthrough of the rubric, including details that appeared and were discussed during the master coding.
Self-Evaluation
The self-evaluation section is the first set of data that annotators receive, immediately after the kickoff call. After coding this set, annotators receive the gold standard codes to compare with their own codes and evaluate their understanding and internalize the nuances of the rubric.
This set should comprise enough data points for annotators to evaluate, roughly 30-50 data points.
Norming
The norming section comprises two sets of roughly 50-100 data points to code. The number of data points to code should meet or exceed the sample size required for reliable results from the chosen IRR analyses.
All annotators code every data point for each set. After each set, master coders lead a debrief call to discuss common pain points, clarify uncertainties, and address areas where annotators frequently disagree or misapply the rubric.
These sets are larger than the Self-Evaluation set, as each set is designed to include enough data for reliable IRR analyses. Performing IRR on each set allows alignment to be tracked and confirmed. When the majority of annotators meet the predetermined IRR cutoff, those who achieved the required reliability graduate to Phase 3, independent coding. If the workforce has not reached the required reliability, additional norming sets should be initiated until alignment is achieved.
Gold standard codes must be obtained for the training and norming to align annotators and run reliability analyses. This begins with master coders attending an introductory call to discuss the rubric with the rubric developers and receive an overview of the annotation platform.
Phase 3: Production and Independent Coding
Once the annotators are vetted and aligned, the project moves into annotating the remainder of the data in two sets to balance speed with ongoing quality assurance: Double Coding and Single Coding.
Double Coding (Quality Benchmarking)
Two annotators code a portion of the remaining data, often around 20 percent. This allows IRR stability to be monitored during production. Codes should be double-blind, ensuring that neither annotator sees the other’s label. A master coder adjudicates any disagreements found during this set, reviewing the conflicting labels and selecting the final gold standard code.
Single Coding (Scalability)
The final volume of data is typically handled through single coding to maximize efficiency with two potential paths:
- Full Single Coding Path: Every data point is coded once by one annotator or master coder, relying on the rigorous norming phase to ensure accuracy.
- Rigorous Path: A small percentage (e.g., 5 percent) of the single-coded data is randomly selected for a double-coded spot-check to confirm that alignment is being maintained throughout the end of the project. The small percentage that is double-coded in this path is handled in the same manner as the Double Coding set, such that two annotators provide codes and disagreements are adjudicated by a master coder. If this path is taken, enough data must be double-coded for reliable IRR analysis results.
Conclusion
A successful rigorous annotation project is an iterative process. By documenting all decisions, providing regular feedback to the workforce, and consistently monitoring alignment, the final dataset can include rigorous annotations and provide a robust, reliable foundation for AI use or research applications.
